
Machine Learning Note
Machine Learning
了解什么是机器学习
摘自https://blog.csdn.net/kenan6545456/article/details/139990438
一、到底什么是机器学习?
1.机器学习的根本原理是什么?
机器学习的根本原理就是是通过让机器自动从庞大的数据中学习和寻找规律的一种过程或者是模式,进而做出预测或者做出决策。这可以通过构建和训练机器学习模型来实现,模型会自动学习从输入到输出之间的映射关系。
可以简单理解为人从一出生就是一张白纸,这张白纸上可能写上任何东西,怎么写,怎么用,怎么判断是非对错,都是在学习中产生的,机器学习算法就像是一个婴儿,它并不了解任何事情,需要从头开始学习。就像婴儿通过观察和经验逐渐学会认识和理解世界一样,机器学习算法的根本原理就是通过对数据的观察和分析来学习和理解不同的模式和规律。
2.机器学习是什么?
机器学习是一种人工智能 (AI)领域的技术和方法,旨在使计算机能够从数据中学习和改进性能,而无需显式地进行编程。机器学习算法通过对大量数据的分析和模式识别,自动发现数据中的规律和趋势,并利用这些规律和趋势来进行预测、分类、聚类等任务。
举个例子:
-
假设你想训练一个机器学习模型来自动识别猫和狗的图片。你可以收集大量的带有标签(指明是猫还是狗)的图片作为训练数据。然后,你可以使用机器学习算法,例如卷积神经网络(Convolutional Neural Network,CNN)

-
让模型通过观察这些图片的特征来学习如何区分猫和狗。在训练过程中,模型会自动学习到猫和狗的特征,例如耳朵的形状、眼睛的位置、颜色等。它会通过分析这些特征与标签之间的关系,逐渐提高自己的准确性。

-
一旦模型训练完毕,你就可以用它来预测新的图片是猫还是狗。当你输入一张新的图片时,模型会自动提取图片的特征,并与之前学到的模式进行对比。然后,它会给出一个预测结果,告诉你这张图片是猫还是狗。
二、机器学习可以分为哪几个阶段?
这部分涉及了很多专业技术名词,搞不懂也暂时用不上,就不放了
- 数据的收集和准备
- 特征选择和提取
- 模型选择和训练
- 模型评估和调优
- 部署和应用
三、机器学习有什么用
机器学习在很多领域都有广泛应用,将是未来发展的方向,大势所趋
比如:自动驾驶、推荐系统、金融领域、医疗保健、自然语言处理等各行各业都能够用得到,这就是财富密码!
就连成立于1993年的英伟达,最初以制造处理图形的计算机芯片而闻名,特别是用于电脑游戏。早在AI革命之前,该公司就开始在其芯片中添加有助于机器学习的功能,这帮助它增加了市场份额。现在,它被视为观察AI技术在商业世界中传播速度的重要公司。其CEO黄仁勋也将这一转变称为“下一个工业革命”的曙光。人工智能热潮推动英伟达(Nvidia)市值攀升,已经使其成为全球第一大市值公司!
二十年互联网革命里程碑经历了包括万维网诞生、互联网浏览器普及、谷歌成立、社交媒体兴起、智能手机普及、移动应用繁荣、云计算兴起、共享经济兴起、区块链技术兴起、机器学习、人工智能AI突破。千万别再说三十年河东三十年河西了,互联网高速发展的这二十年,已经改变得太多太多了,技术变革,日新月异!

Machine Learning Specialization——吴恩达机器学习
第一章
1.1欢迎来到机器学习!
举了一些机器学习在生活中的例子
1.2机器学习的应用
- 机器学习是人工智能的一个子领域
- 人工通用智能(Artificial General Intelligence,or AGI)与人一样聪明的机器
第二章
2.1什么是机器学习?
阿瑟塞缪尔定义:最早的机器学习定义,但非正式
机器学习算法(Machine learning algorithms)
-
监督学习(最多使用)(Superbised learning)
-
无监督学习(Unsupervised learning)
-
强化学习(用的不多)(Reinforcement learning)
课程好像不会详细介绍强化学习,先贴个链接
https://blog.csdn.net/weixin_45560318/article/details/112981006
应用学习算法的使用建议
学习工具及怎样有效使用
2.2监督学习Part 1
定义
监督学习是指从输入x到输出y中映射的算法,关键是训练者给机器提供的输入样本
示例:
| 输入(x) | 输出(y) | 应用 |
|---|---|---|
| 各种邮件 | 是否为垃圾邮件 | 垃圾邮件分类器 |
| 音频 | 音频的文本内容 | 语音识别 |
| 英文 | 其他语言 | 翻译器 |
| 广告、用户信息 | 用户是否点击了广告 | 在线广告 |
| 图像、雷达… | 道路信息 | 自动驾驶 |
| 工业产品的图像 | 产品的损坏程度 | 目视检查 |
经过训练后,机器可以对全新的输入x输出适当的对应输出y
回归(Regression)
回归是监督学习算法的其中一个类型,它可以根据输入的数字,按照一定目的,从无数多种数字中选出适当的数字输出。
回归类型有很多种算法,如拟合直线、拟合曲线等,合适的算法会给出更合适的输出
2.3监督学习Part2
分类(Classification)
分类是监督学习算法的另一个类型,可以根据输入的数据,按照设计目的,输出输入数据所属的类别
示例:肿瘤严重程度的判断
训练者可以根据提供肿瘤的大小,作为一个判断标准,判断肿瘤属于良性还是恶性
当然,输入数据可以输入多种,如在判断肿瘤严重程度中年龄也是一个重要的判断标准,输入数据越多,机器分类的精度越高

同样的,也可以划分不仅两种输出类别
2.4无监督学习Part1
无监督学习与监督学习都有着各自的功能,并不会因为"无"而比监督算法低级

定义
“无监督”指的是训练者不希望机器根据输入的数据和目的,给出任何适当的输出,而是发现输入数据中可能存在什么模式或结构
聚类算法(Clustering Algorithm)
聚类算法是无监督学习中的一种算法,它能够将数据集(输入的数据)中未标记的数据放入不同的集群中
示例:Google news
Google news会每天查看互联网上数十万篇新闻文章,并将相关故事组合在一起

Google news中的聚类算法从当天互联网上的数十万篇新闻文章中,找到提到相似词的文章并将它们分组到集群中,并自行计算出哪些词按时某些文章属于同一组,而这个过程是完全没有训练者介入的,因此其被称为无监督学习
视频中还有两个便于理解的例子,这里不多赘述,给你链接和时间
4:25
2.5无监督学习Part2
无监督学习的分类
-
聚类算法(Clustering)
上文所述
-
异常检测算法(Anomaly detection)
用于检测异常事件,用于金融系统中的欺诈检测
-
降维算法(Dimensionality reduction)
将一个大数据集压缩为一个小得多的数据集,同时丢失尽可能少的信息
2.6Jupyter Notebooks
可以用shift+enter运行Jupyter Notebooks中的代码
第三章
3.1线性回归模型(linear regression)Part1
术语
训练集:用于训练模型的数据
输入(input):写作"x",也称输入变量(input variable)、特征或输入特征(feature)
输出(output):写作"y",也称输出变量(output variable)、目标变量(target variable)
训练样本总数(number of training examples):写作"m"
单个训练示例(single training example):写作(x,y)
第i个训练示例(i^th^training example):写作(x^(i)^,y^(i)^)
3.2线性回归模型Part2
监督学习的工作过程
-
准备带有输入特征和目标变量的训练集
-
输入到监督学习算法中
-
产生带有函数的模型
函数(function):写作f,可以根据输入特征进行估计和预测
y-hat:是y(目标变量)的估计和预测(estimated y),由函数输出
线性回归函数的表示
f~w,b~=wx+b或者f(x)
可被称为具有单一变量的线性回归(Linear regression with one variable),或单变量线性回归(Univariate linear regression)
3.3代价函数
模型参数(Model parameters)
线性回归模型f~w,b~=wx+b中的w,b被称为模型的参数(可调整的),也被称为系数(coeffeicients)或权重(weights)。
不同的参数可以汇出不同的图表中的直线,而对于同一训练集汇出的图表时,不同的直线得出的y的预测值不同,即不同的参数汇出的直线与训练集数据的拟合程度不同
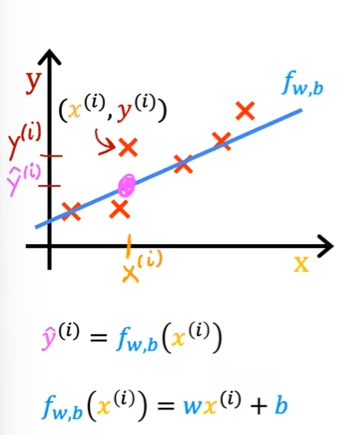
成本函数(Cost function)
用于衡量一条直线与训练数据的拟合程度
- 误差(error):y的预测值 - y
平方误差成本函数
线性回归最常用的成本函数,要使拟合程度越高,就要不断调整模型参数,使平方误差成本函数值越小
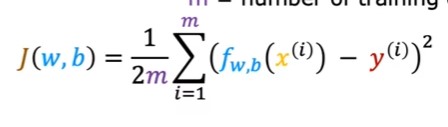
3.4代价函数的直观理解
这节课就是帮助你理解成本函数怎么工作的,直接看视频更直观
(绝不是我想偷懒)

3.5可视化代价函数
3D化的J(w,b)函数
利用绘制3D的J(w,b)图像,找到拟合程度最高的模型参数
等高线化的J(w,b)函数
类似于地理中的等高线图,将3D化的J(w,b)函数经过相同处理后得到的数值同样可以得到拟合程度高的模型参数

一种更直观看出拟合程度高的模型参数的2D图表
3.6可视化的例子
还是举出了更多的例子便于理解


